Hipótesis estadísticas. Test de Hipótesis
Contrastes
de hipótesis
Para controlar los errores aleatorios, además del cálculo de
intervalos de confianza, contamos con una segunda herramienta en el proceso de
inferencia estadística: los test o contrastes de hipótesis à de manera que con los
resultados obtengamos podemos rechazar o no la hipótesis nula, es decir, si hay
relación o no entre las variables.
Con los intervalos nos hacemos una idea de un parámetro de
una población dado un par de números entre los que confiamos que esté el valor
desconocido.
Con los contrastes de hipótesis la estrategia es la
siguiente:
- Establecemos a priori una hipótesis cerca del valor del parámetro.
- Realizamos la recogida de datos
- Analizamos la coherencia de entre la hipótesis previa y los datos obtenidos
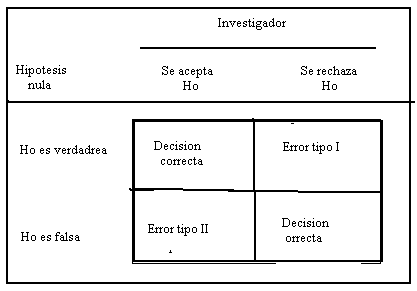
Errores de hipótesis
En este tema estudiamos de nuevo el test de Chi cuadrado, ya explicado anteriormente, dejo aquí un ejemplo para aclararlo de nuevo,
En un C de Salud analizamos las historias de enfermería (292 hombres y 192 mujeres). De ellos tienen úlcera 10 hombres y 24 mujeres y no tienen 282 y 168 respectivamente. Nivel de significación 0, 05. Las hipótesis serías:
– Ho: No existe relación entre tener úlcera y el sexo.
– H1: Sí existe relación entre tener úlcera y el sexo.
Paso 1: Realizar la tabla de las frecuencias observadas y calcular los valores esperados


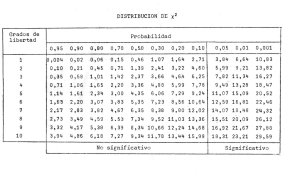
Paso 2: Calcular los grados de libertad.
Grados de libertad = (nº de filas – 1) por (nº de columnas – 1)
Grados de libertad = (2 – 1)(2 – 1) = 1 x 1 = 1
Paso 3: Calcular el valor de chi cuadrado.

Paso 6: Comparar los valores.
– Valor calculado –> 14, 61
– Valor de la tabla –> 3, 84
Conclusión: como 14, 61 > 3, 84, rechazamos Ho y ACEPTAMOS H1.